ECLiPSe CLPで機械の買い換え問題(Problems and exercises in Operations Researchの1.5 Renewal plan)を解くプログラムの説明をします。
問題:
ある会社が12000ユーロの機械を購入し使用しています。機械には毎年維持費(costs)がかかります(維持費は年々上がっていきます)。
使用中の機械は中古で販売(gain)し新しく買いなおすこともできます(中古機械の販売価格は年々下がっていきます)
維持費と中古機械の販売価格は以下の表のとおりになっています(1keuroは1000ユーロ)。
5年間の総運用コストを最小限に抑える機械の買い換え計画を決定しなさい。
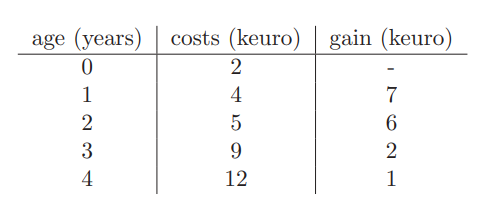
行間を読むとこの問題は機械の生産する利益に関しては触れられていないのでこれは毎年一定で考慮する必要なしということのようです。
難しくて解けなかったので答えと解説を見ました。説明します。
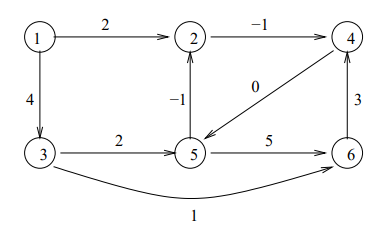
「i年目に購入した機械をj年目まで使用し、買い替えたときのコスト」をCijという変数で表し、1~6年目時点を表す6つのノードがCijで結ばれた有向グラフを考える(6は5年間の期限終了時を表す)
Cijの計算方法は以下となります。
Cij = 12000 + [(j-i)年間にかかった維持費] – [(j-i)年使用した機械の中古販売価格]
たとえば 2年目に購入した機械を4年目まで使用し買い替えたコストだと
C24 = 12000 + (2000+4000) – 6000 = 12000
となります。これはノード2とノード4を結ぶエッジとなります。
そのように計算した有向グラフは以下のようになります(回答からコピー)
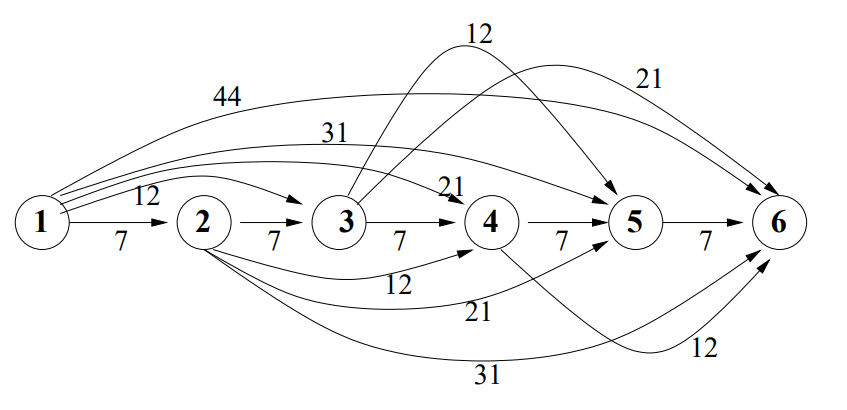
このようなグラフの、ノード1からノード6へ至る最小コストの経路が答えとなります。
single_pair_short_path/6を使用すると、最小コストの経路をすべて取得できます。
single_pair_short_path(+Graph, +DistanceArg, +SourceNode, +SinkNode, +Tolerance, -Path)
+Tolerance を 0にするとすべての最小コストの経路が取得され、当然それらのコストはみな同じとなります。
+Tolerance に0より大きい数値を設定すると、最小+その値 までのコストの経路も抽出されるようです。
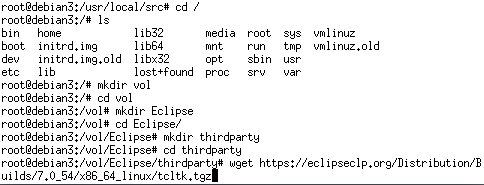
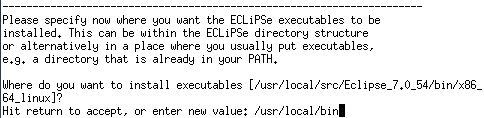
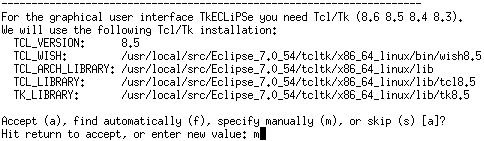
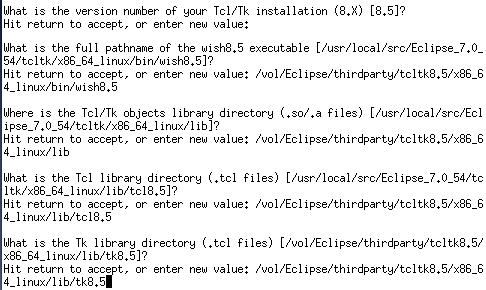
プログラム
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
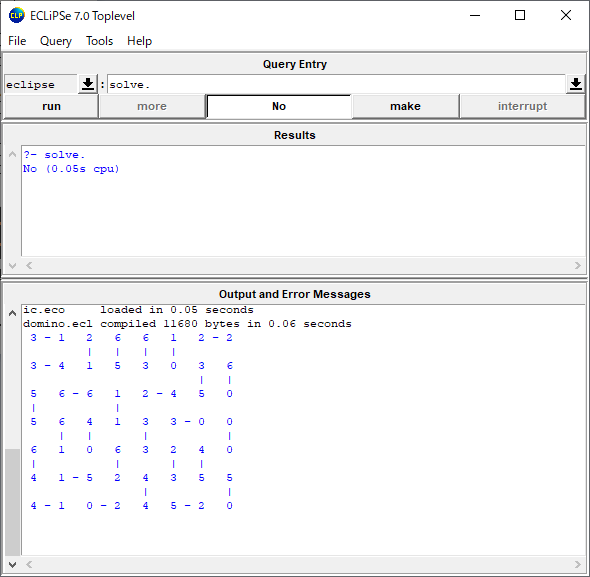
:-lib(graph_algorithms). solve(Path):- make_graph(6, [ e(1,2,7), e(1,3,12), e(1,4,21), e(1,5,31), e(1,6,44), e(2,3,7), e(2,4,12), e(2,5,21), e(2,6,31), e(3,4,7), e(3,5,12), e(3,6,21), e(4,5,7), e(4,6,12), e(5,6,7) ],Graph), single_pair_short_path(Graph, 0, 1, 6, 0, Path). |
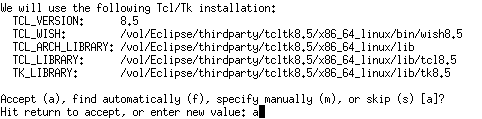
実行結果:
|
1 2 3 4 5 6 7 |
?- solve(Path). Path = 31 - [e(5, 6, 7), e(3, 5, 12), e(1, 3, 12)] Yes (0.00s cpu, solution 1, maybe more) Path = 31 - [e(4, 6, 12), e(3, 4, 7), e(1, 3, 12)] Yes (0.00s cpu, solution 2, maybe more) Path = 31 - [e(4, 6, 12), e(2, 4, 12), e(1, 2, 7)] Yes (0.00s cpu, solution 3) |
コストは31(=31000ユーロ)が最小で、以下の買い換え計画があるようです。
3年目と5年目で買い替える
3年目と4年目で買い替える
2年目と4年目で買い替える