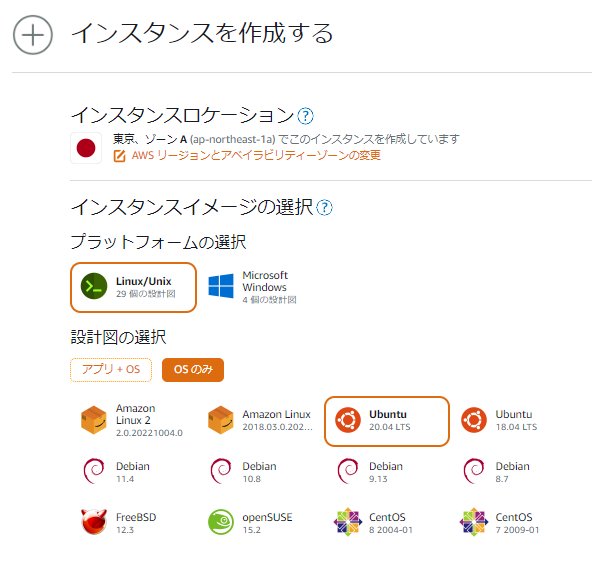
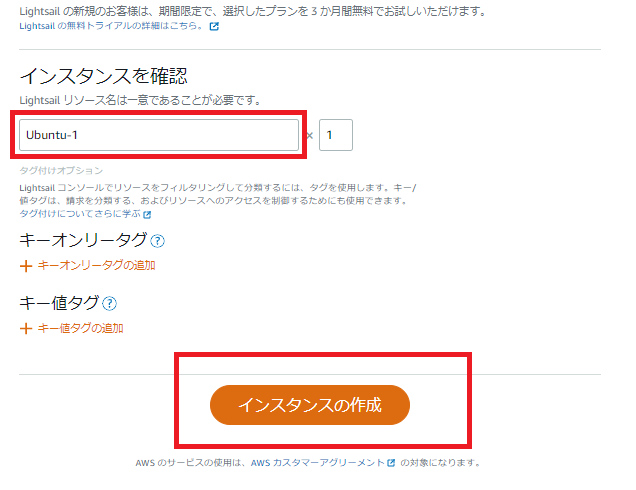
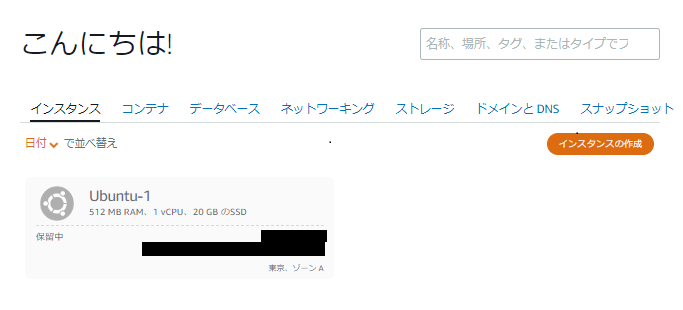
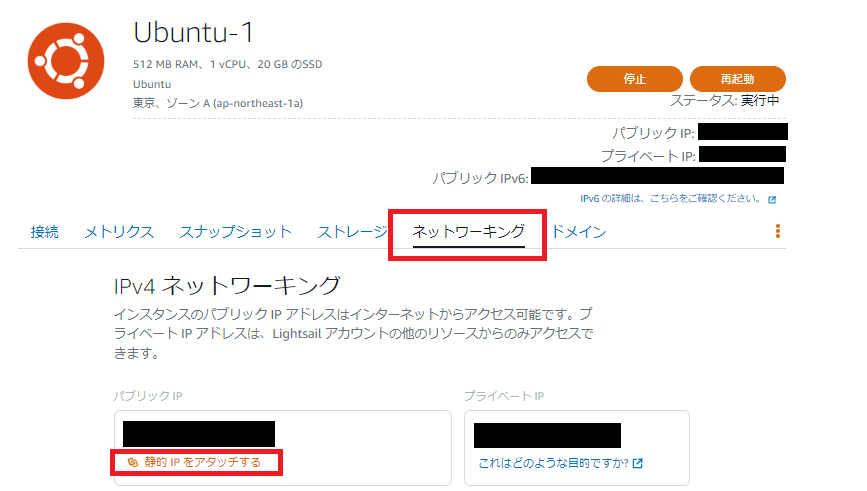
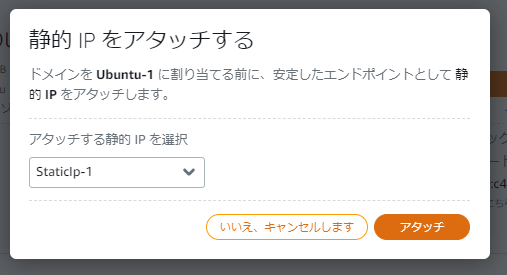
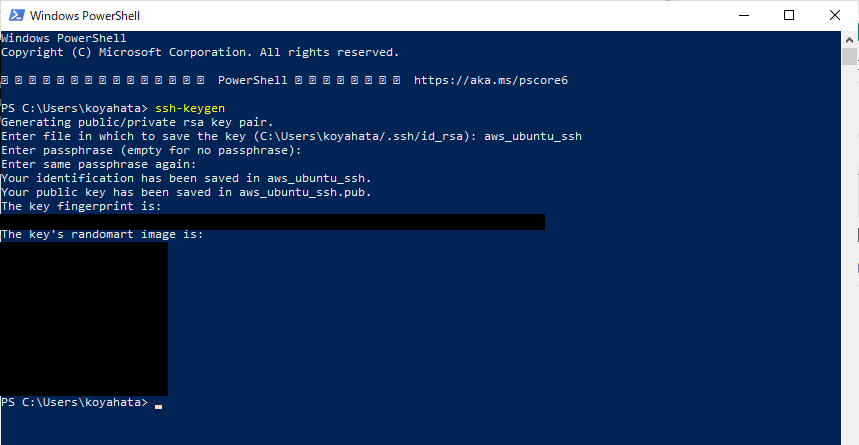
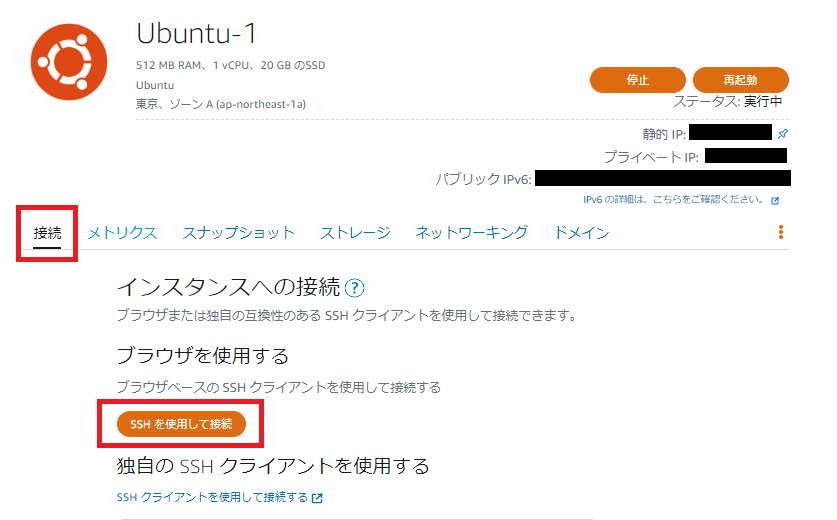
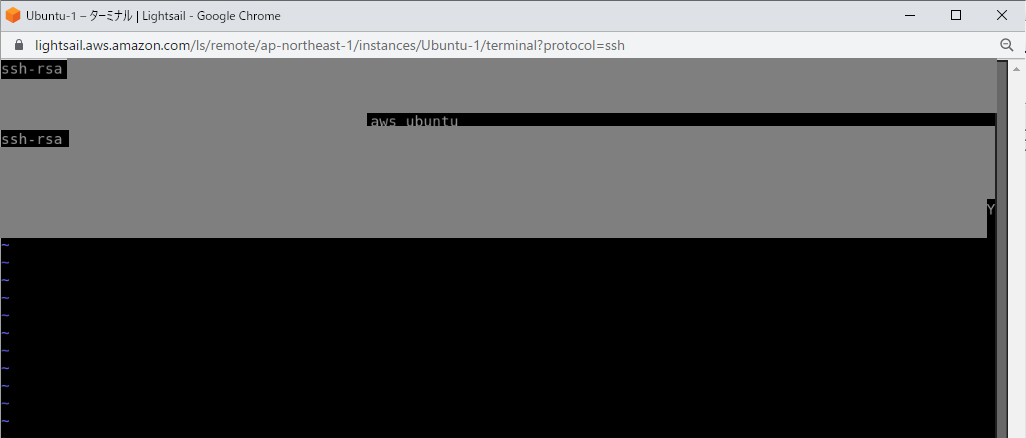
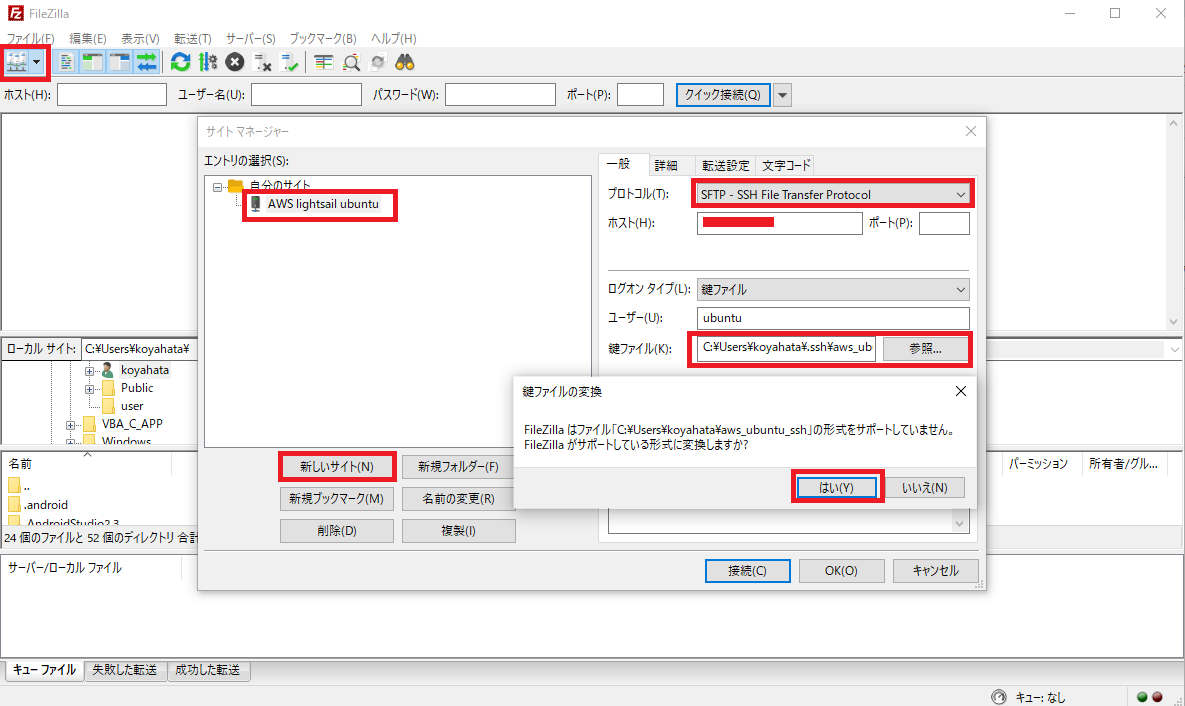
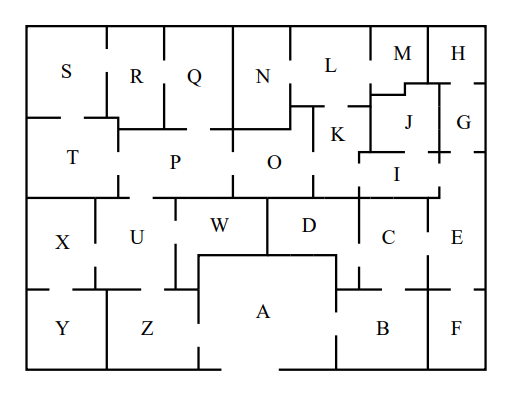
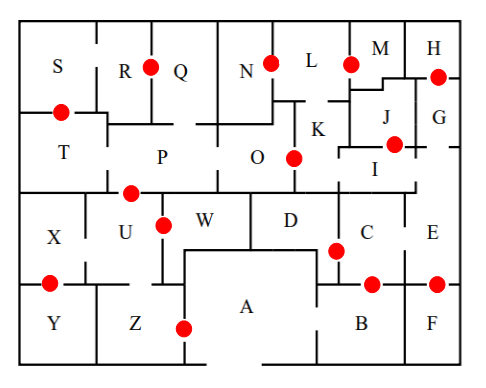
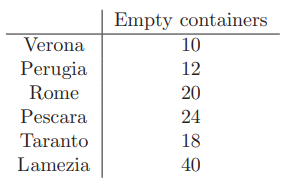
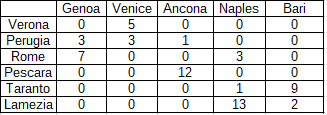
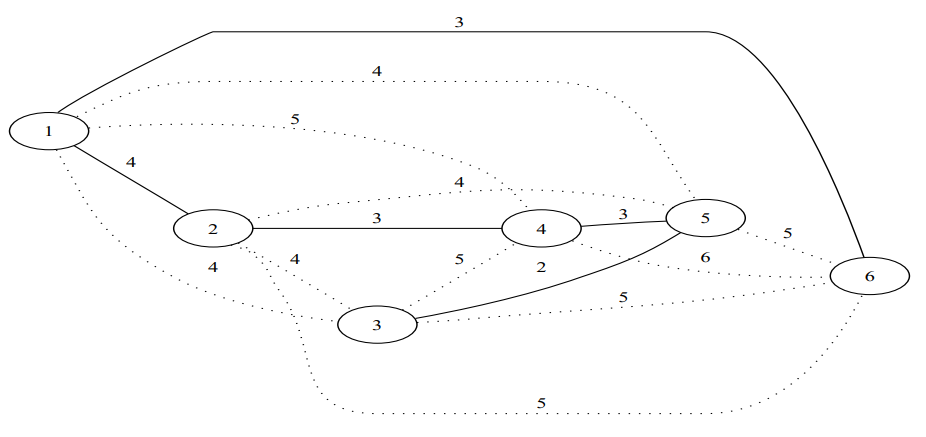
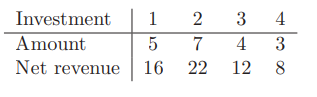?- solve(Ans).
Ans = [0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.00s cpu, solution 1, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.02s cpu, solution 2, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.02s cpu, solution 3, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.02s cpu, solution 4, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.02s cpu, solution 5, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.02s cpu, solution 6, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.02s cpu, solution 7, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.02s cpu, solution 8, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.02s cpu, solution 9, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.02s cpu, solution 10, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.02s cpu, solution 11, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.02s cpu, solution 12, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 13, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 14, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 15, maybe more)
Ans = [0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 16, maybe more)
Ans = [0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 17, maybe more)
Ans = [0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 18, maybe more)
Ans = [1, 0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 19, maybe more)
Ans = [1, 0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 20, maybe more)
Ans = [1, 0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 21, maybe more)
Ans = [1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 22, maybe more)
Ans = [1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 23, maybe more)
Ans = [1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 24, maybe more)
Ans = [1, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 25, maybe more)
Ans = [1, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 26, maybe more)
Ans = [1, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 27, maybe more)
No (0.03s cpu)
Found a solution with cost 14
Found no solution with cost 8.0 .. 13.0
0,1,1,0,1,1,0,0,0,1,0,1,1,0,0,1,1,0,0,1,0,1,0,1,1,1,
0,1,1,0,1,1,0,0,0,1,0,1,1,0,0,1,1,0,0,1,0,1,1,0,1,1,
0,1,1,0,1,1,0,0,0,1,0,1,1,0,0,1,1,0,0,1,1,0,1,0,1,1,
0,1,1,0,1,1,0,0,1,0,1,1,1,0,0,1,1,0,0,1,0,1,0,1,1,0,
0,1,1,0,1,1,0,0,1,0,1,1,1,0,0,1,1,0,0,1,0,1,1,0,1,0,
0,1,1,0,1,1,0,0,1,0,1,1,1,0,0,1,1,0,0,1,1,0,1,0,1,0,
0,1,1,0,1,1,0,0,1,1,0,1,1,0,0,1,1,0,0,1,0,1,0,1,1,0,
0,1,1,0,1,1,0,0,1,1,0,1,1,0,0,1,1,0,0,1,0,1,1,0,1,0,
0,1,1,0,1,1,0,0,1,1,0,1,1,0,0,1,1,0,0,1,1,0,1,0,1,0,
0,1,1,0,1,1,0,1,0,1,0,1,1,0,0,1,1,0,0,1,0,1,0,1,1,0,
0,1,1,0,1,1,0,1,0,1,0,1,1,0,0,1,1,0,0,1,0,1,1,0,1,0,
0,1,1,0,1,1,0,1,0,1,0,1,1,0,0,1,1,0,0,1,1,0,1,0,1,0,
0,1,1,0,1,1,1,0,1,0,0,1,1,0,0,1,1,0,0,1,0,1,0,1,1,0,
0,1,1,0,1,1,1,0,1,0,0,1,1,0,0,1,1,0,0,1,0,1,1,0,1,0,
0,1,1,0,1,1,1,0,1,0,0,1,1,0,0,1,1,0,0,1,1,0,1,0,1,0,
0,1,1,1,1,1,0,0,0,1,0,1,1,0,0,1,1,0,0,1,0,1,0,1,1,0,
0,1,1,1,1,1,0,0,0,1,0,1,1,0,0,1,1,0,0,1,0,1,1,0,1,0,
0,1,1,1,1,1,0,0,0,1,0,1,1,0,0,1,1,0,0,1,1,0,1,0,1,0,
1,0,0,1,1,1,0,1,0,1,0,1,1,0,0,1,1,0,0,1,0,1,0,1,1,0,
1,0,0,1,1,1,0,1,0,1,0,1,1,0,0,1,1,0,0,1,0,1,1,0,1,0,
1,0,0,1,1,1,0,1,0,1,0,1,1,0,0,1,1,0,0,1,1,0,1,0,1,0,
1,0,1,0,1,1,0,1,0,1,0,1,1,0,0,1,1,0,0,1,0,1,0,1,1,0,
1,0,1,0,1,1,0,1,0,1,0,1,1,0,0,1,1,0,0,1,0,1,1,0,1,0,
1,0,1,0,1,1,0,1,0,1,0,1,1,0,0,1,1,0,0,1,1,0,1,0,1,0,
1,1,0,1,1,1,0,0,0,1,0,1,1,0,0,1,1,0,0,1,0,1,0,1,1,0,
1,1,0,1,1,1,0,0,0,1,0,1,1,0,0,1,1,0,0,1,0,1,1,0,1,0,
1,1,0,1,1,1,0,0,0,1,0,1,1,0,0,1,1,0,0,1,1,0,1,0,1,0,