LinuxでECLiPSe CLPをビルドする手順を書きます。
何でビルドするかというと、先日ECLiPSeのメイン開発者の Joachim Schimpf さんに「ECLiPSeのContributorになりたい」というメールを送ったら、「ビルド・インストール関連の作業でできることがたくさんあり、例えばDebian packageなど出来ればよい(今は./RUNMEという独自シェルスクリプトでインストールする)」と言われたので、その作業の一環としてやってます。ビルドのやり方を記事にまとめるのも立派なContribute作業だと思いますので以下に手順記載します。
ちなみにただインストールするだけならばずっと簡単な手順があり、そのうち紹介します。
ディストリビューション:Debian バージョン10.9
ECLiPSe CLPのバージョン:7.0_54
目標:ダウンロードしたソースから、root以外の全ユーザーがtkeclipseコマンドでtkeclipse起動・eclipseコマンドでeclipse起動できる状態までもっていく
この作業でできないこと:
COIN-ORのインストール
CPLEXのインストール
XPRESS-MPのインストール
JAVAインターフェースのインストール
GraphVizのインストール
FlexLMのインストール
MySQLインターフェースのインストール
ディレクトリ構成やアーキテクチャ(以下の例では64bit)など、適宜自分の環境に読み替えてください。また、ソースをビルド・インストールする際はソースディレクトリのINSTALLファイルなど目を通しておいてください。
以下はDebianをインストールした直後からの手順です。基本rootで作業してます。
ECLiPSeダウンロードページ
/usr/local/srcに移動し、wgetでECLiPSeのソースを取得し、解凍する

build essential をインストールする
![]()
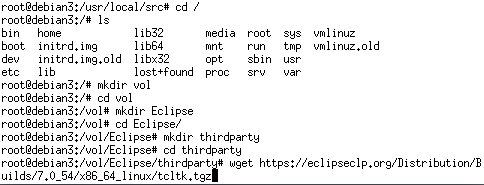
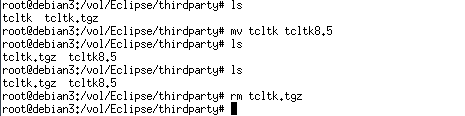
mkdir /vol/Eclipse/thirdparty を作成し、ECLiPSeのサーバからtcltk.tgzを取得・解凍する(最新の8.6のライブラリだとコンパイルエラーとなるのでここで手に入る8.5を使用します)
![]()
ディレクトリの名称をtcl8.5に変更します
m4をインストールします(次のGMPのビルドで必要となる)
![]()
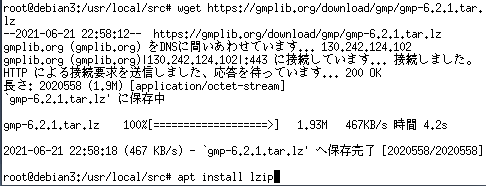
GMPのソースを取得、解凍します。lzファイルの解凍のためにlzipインストールします。
![]()
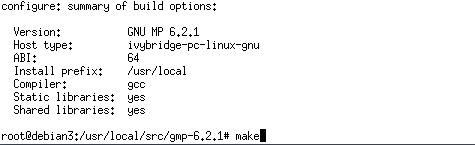
gmpのフォルダに入り./configureを実行

makeを実行
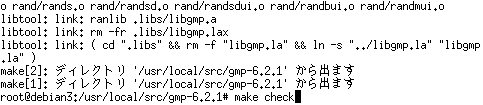
make checkを実行
make instalを実行

はじめにダウンロードしたEclipseのソースのフォルダに移動します。
ECLIPSEARCH=x86_64_linux
ECLIPSETHIRDPARTY=/vol/Eclipse/thirdparty
を設定したのち、./configureを実行(詳しくは同じフォルダのINSTALLというファイル見てください)

make -f Makefile.$ECLIPSEARCH を実行
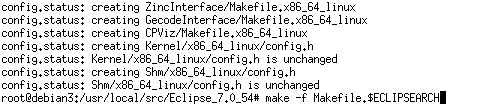
./RUNMEを実行
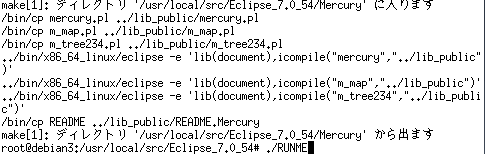
Enter押下

Enter押下
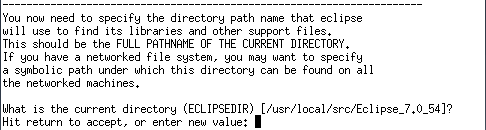
インストール先は/usr/local/binにしました。
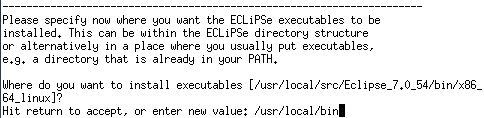
Enter
![]()
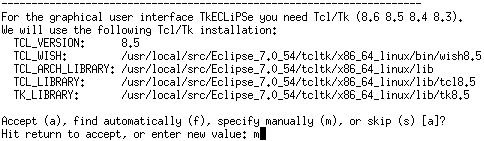
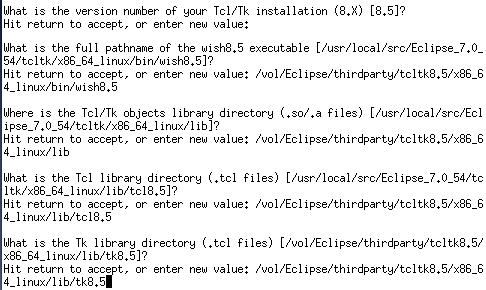
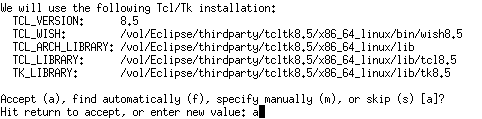
tcl/tk用のパス設定を行います。多分このままで良いのですが、一応配置した/vol/Eclipse/thirdpartyに変更しました。
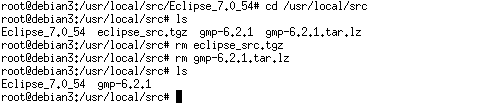
不要となった圧縮ファイルを削除します。
exitで一般ユーザーに戻り「tkeclipse」コマンドでtkeclipseが、「eclipse」コマンドでeclipseが起動するようになりました。