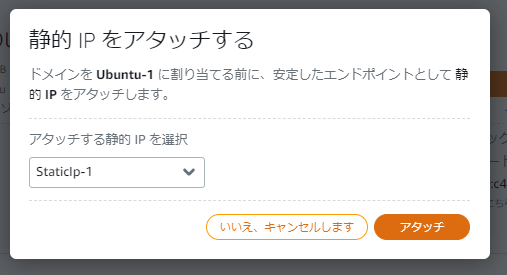
ECLiPSe CLPで以下の美術館の警備員配置問題を解きます。
問題(Problems and exercises in Operations Researchの4.7 Museum Guards):
以下のような部屋構成の美術館に警備員を配置せよ。
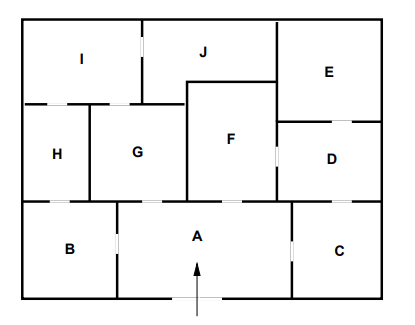
条件:
・コスト削減のため警備員は各部屋をつなぐドアの位置に配置し2つの部屋を同時に警備する。
・どの部屋も少なくとも1人の警備員が見張っているようにする。
・上記条件を満たしつつ、なるべく少ない警備員で警備する。
プログラム:
:-lib(ic).
:-lib(branch_and_bound).
solve(Vars):-
Graph =
[](
[](a,b,N1),
[](a,g,N2),
[](a,f,N3),
[](a,c,N4),
[](b,h,N5),
[](c,d,N6),
[](d,e,N7),
[](d,f,N8),
[](g,i,N9),
[](h,i,N10),
[](i,j,N11)
),
Nodes = [a,b,c,d,e,f,g,h,i,j],
Vars=[N1,N2,N3,N4,N5,N6,N7,N8,N9,N10,N11],
Vars#::0..1,
(
foreach(Node,Nodes),param(Graph)
do
(
(
foreacharg([](P1,P2,P3),Graph), fromto(0,In,Out,OutFormula), param(Node)
do
(
P1==Node->
Out = In+P3;
(
P2==Node->
Out=In+P3;Out=In
)
)
),
ic:(eval(OutFormula)#>=1)
)
),
ic:(Sum #= sum(Vars)),
bb_min(labeling(Vars),Sum,bb_options{timeout:60,solutions:all}).
実行結果:
?- solve(Ans).
Ans = [0, 0, 0, 1, 1, 0, 1, 1, 1, 0, 1]
Yes (0.00s cpu, solution 1, maybe more)
Ans = [0, 0, 1, 0, 1, 1, 1, 0, 1, 0, 1]
Yes (0.00s cpu, solution 2, maybe more)
Ans = [0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1]
Yes (0.00s cpu, solution 3, maybe more)
Ans = [0, 1, 0, 0, 1, 1, 1, 1, 0, 0, 1]
Yes (0.00s cpu, solution 4, maybe more)
Ans = [0, 1, 0, 1, 1, 0, 1, 1, 0, 0, 1]
Yes (0.00s cpu, solution 5, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 1, 0, 0, 0, 1]
Yes (0.00s cpu, solution 6, maybe more)
Ans = [0, 1, 1, 1, 1, 0, 1, 0, 0, 0, 1]
Yes (0.00s cpu, solution 7, maybe more)
No (0.00s cpu)
Found a solution with cost 6
Found no solution with cost 2.0 .. 5.0
解答配置(の一つ)
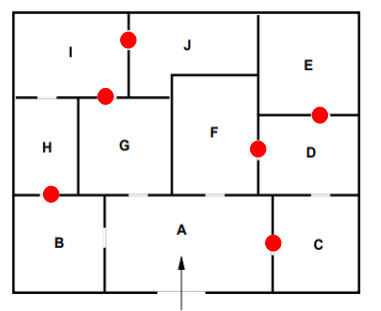
解説:
まず部屋をノード、ドアをエッジと考えたグラフを作成し、エッジごとに警備員がいるかいないかを表す変数を宣言します。警備員がいれば1、いなければ0。
Nodesに全部屋のリストを用意しておいて(20行目)、
それをひとつづつ指定したループを処理します(25行目)
ループ中ではエッジ配列の中で指定した部屋を持つものを探し、警備員有無の変数をすべて足し合わせます(29行目からのループ)。ある部屋に注目したとき、そのすべてのドアに対応する警備員変数を足し合わせた式を作ります。少なくとも1つのドアには警備員がいるはずなのでこの式に「1以上」の制約をつけます(40行目)
警備員の数を最小にするのが目標なので警備員有無変数の配列Varsの合計が最小になるように指定し分枝限定法(branch_and_bound)を用いてVarsの値を求めます。
実行結果を見るとわかる通り、最小コストは6で、7つの解があるようです。
もう一つ、以下のもっと複雑な部屋割りの場合も解いてみます。
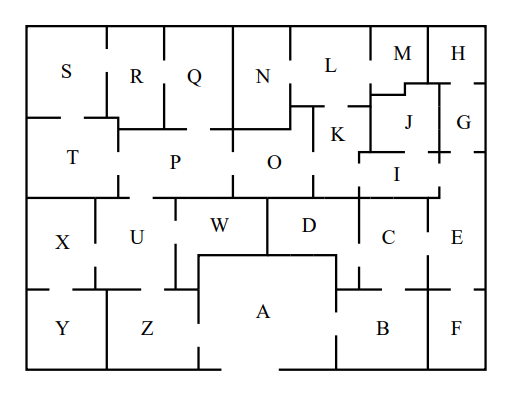
プログラム:
:-lib(ic).
:-lib(branch_and_bound).
solve(Vars):-
Graph =
[](
[](s,r,N1),
[](s,t,N2),
[](r,q,N3),
[](q,p,N4),
[](n,l,N5),
[](l,m,N6),
[](l,k,N7),
[](t,p,N8),
[](p,o,N9),
[](o,k,N10),
[](k,i,N11),
[](j,i,N12),
[](h,g,N13),
[](g,e,N14),
[](x,u,N15),
[](u,w,N16),
[](d,c,N17),
[](i,e,N18),
[](c,e,N19),
[](x,y,N20),
[](u,z,N21),
[](z,a,N22),
[](a,b,N23),
[](b,c,N24),
[](e,f,N25),
[](p,u,N26)
),
Nodes = [a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,w,x,y,z],
Vars=[N1,N2,N3,N4,N5,N6,N7,N8,N9,N10,N11,N12,N13,N14,N15,N16,N17,N18,N19,N20,N21,N22,N23,N24,N25,N26],
Vars#::0..1,
(
foreach(Node,Nodes),param(Graph)
do
(
(
foreacharg([](P1,P2,P3),Graph), fromto(0,In,Out,OutFormula), param(Node)
do
(
P1==Node->
Out = In+P3;
(
P2==Node->
Out=In+P3;Out=In
)
)
),
ic:(eval(OutFormula)#>=1)
)
),
ic:(Sum #= sum(Vars)),
bb_min(labeling(Vars),Sum,bb_options{timeout:60,solutions:all}),
(
fromto(Vars,[First|Rest],Rest,[])
do
write(First),write(",")
),nl.
実行結果:
?- solve(Ans).
Ans = [0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.00s cpu, solution 1, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.02s cpu, solution 2, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.02s cpu, solution 3, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.02s cpu, solution 4, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.02s cpu, solution 5, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.02s cpu, solution 6, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.02s cpu, solution 7, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.02s cpu, solution 8, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.02s cpu, solution 9, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.02s cpu, solution 10, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.02s cpu, solution 11, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.02s cpu, solution 12, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 13, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 14, maybe more)
Ans = [0, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 15, maybe more)
Ans = [0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 16, maybe more)
Ans = [0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 17, maybe more)
Ans = [0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 18, maybe more)
Ans = [1, 0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 19, maybe more)
Ans = [1, 0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 20, maybe more)
Ans = [1, 0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 21, maybe more)
Ans = [1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 22, maybe more)
Ans = [1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 23, maybe more)
Ans = [1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 24, maybe more)
Ans = [1, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 25, maybe more)
Ans = [1, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 26, maybe more)
Ans = [1, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, ...]
Yes (0.03s cpu, solution 27, maybe more)
No (0.03s cpu)
Found a solution with cost 14
Found no solution with cost 8.0 .. 13.0
0,1,1,0,1,1,0,0,0,1,0,1,1,0,0,1,1,0,0,1,0,1,0,1,1,1,
0,1,1,0,1,1,0,0,0,1,0,1,1,0,0,1,1,0,0,1,0,1,1,0,1,1,
0,1,1,0,1,1,0,0,0,1,0,1,1,0,0,1,1,0,0,1,1,0,1,0,1,1,
0,1,1,0,1,1,0,0,1,0,1,1,1,0,0,1,1,0,0,1,0,1,0,1,1,0,
0,1,1,0,1,1,0,0,1,0,1,1,1,0,0,1,1,0,0,1,0,1,1,0,1,0,
0,1,1,0,1,1,0,0,1,0,1,1,1,0,0,1,1,0,0,1,1,0,1,0,1,0,
0,1,1,0,1,1,0,0,1,1,0,1,1,0,0,1,1,0,0,1,0,1,0,1,1,0,
0,1,1,0,1,1,0,0,1,1,0,1,1,0,0,1,1,0,0,1,0,1,1,0,1,0,
0,1,1,0,1,1,0,0,1,1,0,1,1,0,0,1,1,0,0,1,1,0,1,0,1,0,
0,1,1,0,1,1,0,1,0,1,0,1,1,0,0,1,1,0,0,1,0,1,0,1,1,0,
0,1,1,0,1,1,0,1,0,1,0,1,1,0,0,1,1,0,0,1,0,1,1,0,1,0,
0,1,1,0,1,1,0,1,0,1,0,1,1,0,0,1,1,0,0,1,1,0,1,0,1,0,
0,1,1,0,1,1,1,0,1,0,0,1,1,0,0,1,1,0,0,1,0,1,0,1,1,0,
0,1,1,0,1,1,1,0,1,0,0,1,1,0,0,1,1,0,0,1,0,1,1,0,1,0,
0,1,1,0,1,1,1,0,1,0,0,1,1,0,0,1,1,0,0,1,1,0,1,0,1,0,
0,1,1,1,1,1,0,0,0,1,0,1,1,0,0,1,1,0,0,1,0,1,0,1,1,0,
0,1,1,1,1,1,0,0,0,1,0,1,1,0,0,1,1,0,0,1,0,1,1,0,1,0,
0,1,1,1,1,1,0,0,0,1,0,1,1,0,0,1,1,0,0,1,1,0,1,0,1,0,
1,0,0,1,1,1,0,1,0,1,0,1,1,0,0,1,1,0,0,1,0,1,0,1,1,0,
1,0,0,1,1,1,0,1,0,1,0,1,1,0,0,1,1,0,0,1,0,1,1,0,1,0,
1,0,0,1,1,1,0,1,0,1,0,1,1,0,0,1,1,0,0,1,1,0,1,0,1,0,
1,0,1,0,1,1,0,1,0,1,0,1,1,0,0,1,1,0,0,1,0,1,0,1,1,0,
1,0,1,0,1,1,0,1,0,1,0,1,1,0,0,1,1,0,0,1,0,1,1,0,1,0,
1,0,1,0,1,1,0,1,0,1,0,1,1,0,0,1,1,0,0,1,1,0,1,0,1,0,
1,1,0,1,1,1,0,0,0,1,0,1,1,0,0,1,1,0,0,1,0,1,0,1,1,0,
1,1,0,1,1,1,0,0,0,1,0,1,1,0,0,1,1,0,0,1,0,1,1,0,1,0,
1,1,0,1,1,1,0,0,0,1,0,1,1,0,0,1,1,0,0,1,1,0,1,0,1,0,
解答配置(の一つ)
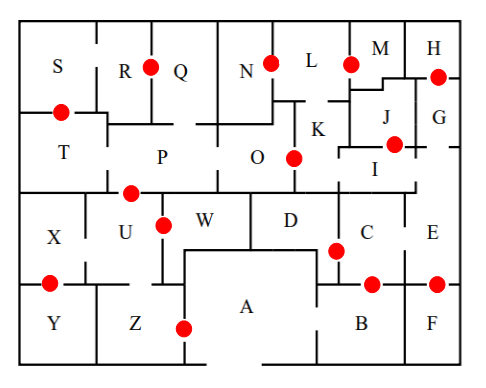
最小コストは14、全部で27通りの解があるようです。