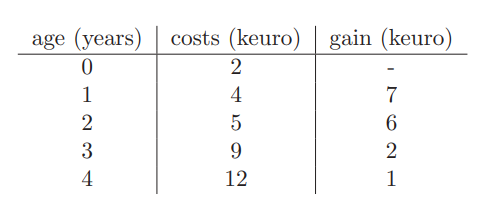
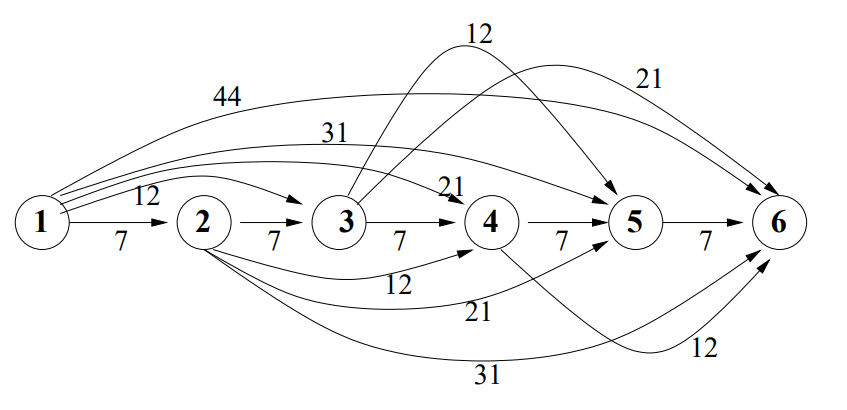
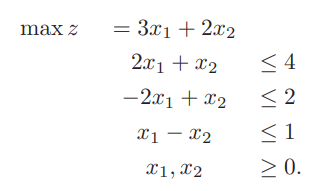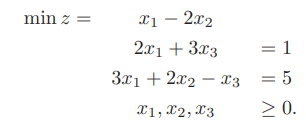ECLiPSe CLPで記述するソルバーの構成はおおまかに以下の部分に分かれます。
1.制約の記述
2.解のサーチ
3.解の表示
2.の解のサーチというのは、具体的には以下の2つのループの入れ子の構造となります。
ループ1:複数の制約変数の中から1つを選択する
ループ2:変数にドメイン内の値を一つ割り当てる
このとき、ループ1で「どのような順番で変数を選択するか」ループ2で「どのような順番で値を決定するか」という2つの制御をおこなうことができます。この記事はループ2の値決定の順番をいろいろ試す記事となります。
ECLiPSe CLPではループ1,ループ2は例えば以下のような方法で記述可能です(他にもあると思いますが)
・labeling/1を使用
ループ1:リストの先頭の変数から選択
ループ2:ドメイン内の数値の小さい値から大きい値へと順に値を決定
・search/6を使用(ループ1、ループ2の制御を一括で指定)
・以下の2つの述語を使用
ループ1:delete/5を使用して値を決める変数を決定
ループ2:indomain/2を使用してどのように変数に値を設定するかを決定
本記事ではsearch/6に関して、「どのような順で変数に値を割り当てるか」というのをオプションを変えながら実験したいと思います。
以下のテスト用プログラムで実験します。
:-lib(ic).
search_test(Choice):-
A #:: 1..10,
search([A], 0, input_order, Choice, complete, []),
write(A),write(','),
fail.
Choice の部分を色々変更することにより実験します。解説の部分は直訳なので自分でも意味わかってない箇所あります。特に「テストされた値を削除」「ドメイン分割」のところが良くわかってません。誰か教えて下さい。
①indomain
組み込みのindomain/1を使用します。値は昇順で試行されます。失敗しても以前にテストされた値は削除されません。
?- search_test(indomain).
No (0.00s cpu)
1,2,3,4,5,6,7,8,9,10,
②indomain_min
昇順で試行されます。失敗すると以前にテストされた値が削除されます。値はindomainの場合と同じ順序でテストされますが、バックトラックがより早く発生する可能性があります。
?- search_test(indomain_min).
No (0.00s cpu)
1,2,3,4,5,6,7,8,9,10,
③indomain_max
値は降順で試行されます。 失敗すると以前にテストされた値が削除されます。
?- search_test(indomain_max).
No (0.00s cpu)
10,9,8,7,6,5,4,3,2,1,
④indomain_reverse_min
indomain_minと同様ですが、選択は逆の順序で試行されます。つまり最小の値が最初にドメインから削除され、それが失敗した場合にのみ、値が割り当てられます。
?- search_test(indomain_reverse_min).
No (0.00s cpu)
10,9,8,7,6,5,4,3,2,1,
⑤indomain_reverse_max
indomain_maxと同様ですが、選択は逆の順序で試行されます。 つまり、最大値が最初にドメインから削除され、それが失敗した場合にのみ、値が割り当てられます。
?- search_test(indomain_reverse_max).
No (0.00s cpu)
1,2,3,4,5,6,7,8,9,10,
⑥indomain_middle
値はドメインの中央から開始して試行されます。 失敗すると以前にテストされた値が削除されます。
?- search_test(indomain_middle).
No (0.00s cpu)
5,6,4,7,3,8,2,9,1,10,
⑦indomain_median
値はドメインの中央値から開始して試行されます。 失敗すると以前にテストされた値が削除されます。
?- search_test(indomain_median).
No (0.00s cpu)
6,7,5,8,4,9,3,10,2,1,
⑧indomain_split
ドメインの下半分を最初に試行して、連続するドメイン分割によって試行されます。 失敗すると、試行された間隔が削除されます。 これは、indomainまたはindomain_minと同じ順序で値を列挙しますが、それより早く失敗する可能性があります(注:解サーチ時はなるべく早く失敗したほうが処理時間が速くなる。早く失敗≒変数の決定の入れ子のループのより外側のループ回数が減ることと同等)
?- search_test(indomain_split).
No (0.00s cpu)
1,2,3,4,5,6,7,8,9,10,
⑨indomain_reverse_split
ドメインの上半分を最初に試行して、連続するドメイン分割によって試行されます。 失敗すると、試行された間隔が削除されます。 これは、indomain_maxと同じ順序で値を列挙しますが、それより早く失敗する可能性があります。
?- search_test(indomain_reverse_split).
No (0.00s cpu)
10,9,8,7,6,5,4,3,2,1,
⑩indomain_random
値はランダムな順序で試行されます。 バックトラック時に、以前に試行された値が削除されます。 このルーチンを使用すると、別の呼び出しで異なる順序で乱数が作成されるため、再現性のない結果が生じる可能性があります。 この方法では、組み込みのrandom / 1を使用して乱数を作成し、seed / 1を使用して別の実行で同じ番号生成シーケンスを強制することができます。
?- search_test(indomain_random).
No (0.00s cpu)
何度も実行(その都度結果が異なる)
8,2,1,7,3,9,10,4,5,6,
4,6,3,10,5,2,1,7,9,8,
7,10,9,4,1,2,3,8,6,5,
10,4,7,6,3,8,5,9,2,1,
10,3,5,7,8,4,1,2,9,6,
⑪indomain_interval
ドメインが複数の間隔で構成されている場合は、最初に間隔の選択で分岐します。 1つの間隔では、ドメイン分割を使用します。
?- search_test(indomain_interval).
No (0.00s cpu)
1,2,3,4,5,6,7,8,9,10,